
内部排序

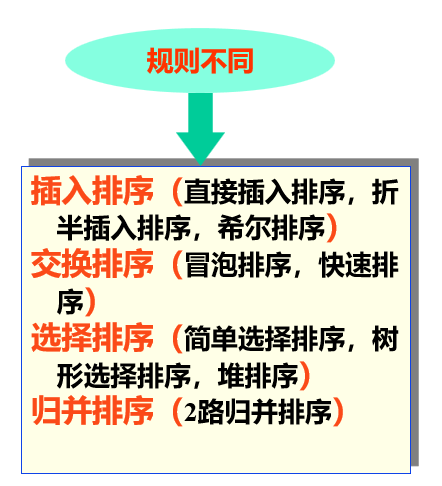
首先区分排序的分类
[根据排序时文件记录的存放位置]
- 内部排序:排序过程中将全部记录放在内存中处理。
- 外部排序:排序过程中需在内外存之间交换信息。
这里我们先学习内部排序
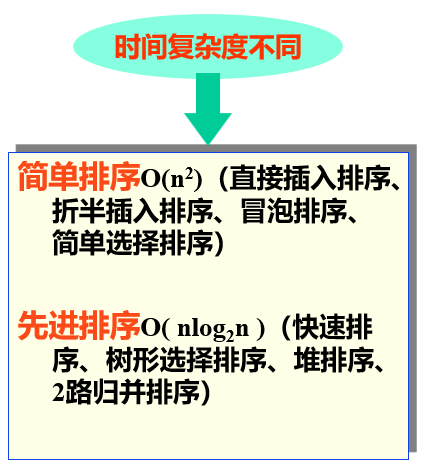
同样的,还有一种排序的分类
[根据排序前后相同关键字记录的相对次序]
- 稳定排序:设文件中任意两个记录的关键字值相同,即Ki=Kj(i!=j),若排序之前记录Ri领先于记录Rj,排序后这种关系不变(对所有输入实例而言)。
- 不稳定排序:只要有一个实例使排序算法不满足稳定性要求。
还有好几种方法不一一赘述,在这里放个图

内部排序
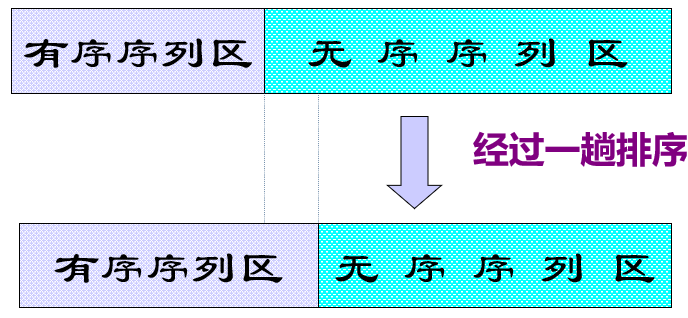
本质:内部排序的过程是一个逐步扩大记录的有序序列长度的过程。
前提约定
- 顺序存储
- 按记录关键字非递减,关键字为整数
1 |
|
插入排序
不同的具体实现方法导致不同的算法描述:
• 直接插入排序 (基于顺序查找)
• 折半插入排序(基于折半查找)
• 表插入排序 (基于链表存储)
• 希尔排序 (基于逐趟缩小增量)
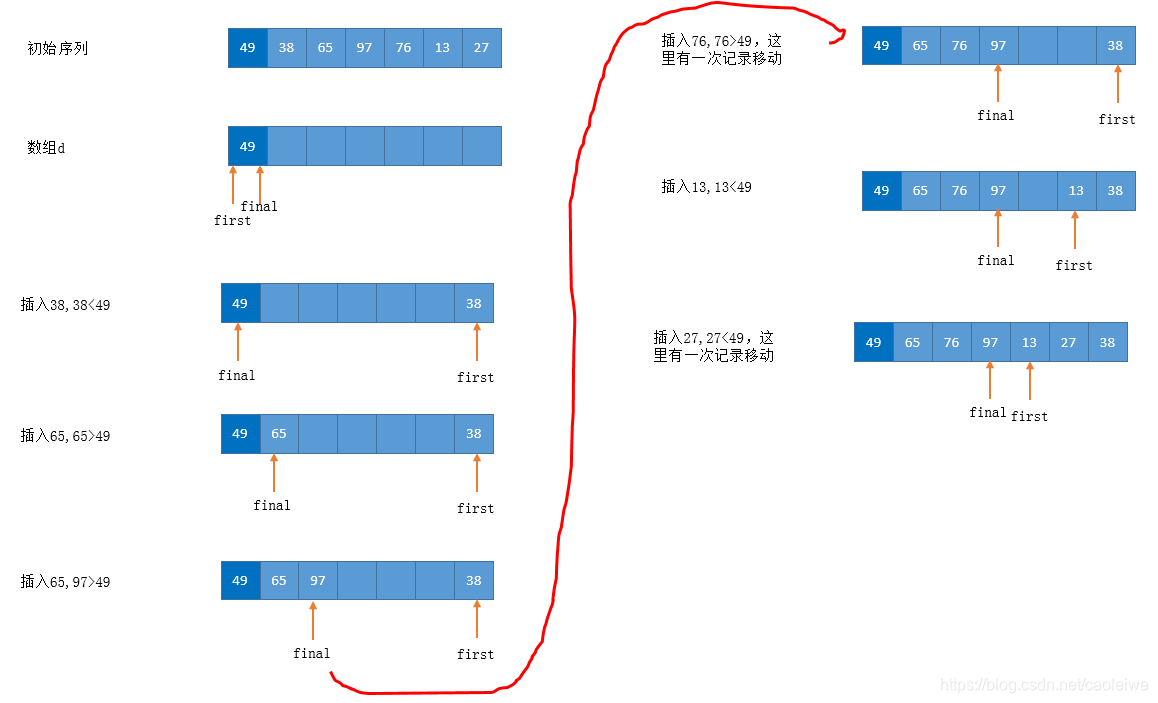
直接插入排序
利用“顺序查找”实现“在R[1..i-1]中查找R[i]的插入位置”
[算法思想] 每次使有序区增加一个记录
- 从后向前找,边找边移动;
- 把R[i]放在R[0]作为哨兵,减少比较次数
折半插入排序
算法思想:将循环中每一次在区间 [1,i-1]上为确定插入位置的顺序查找操作改为折半查找操作。
效果:减少关键字间的比较次数。
2-路插入排序
2-路插入排序可以减少排序过程中移动记录的次数,但为此需要借助n个记录的辅助空间。
算法思想:设置与r同样大小的辅助空间d,将r[1]赋值给d[1],将d看作循环向量。
对于r[i],若r[i]>=d[1],则插入d[1]之后的有序序列中,反之则插入d[1]之前的有序序列中。(避免r[1]关键字最小/最大)
表插入排序
算法思想:构造静态链表,用改变指针来代替移动记录操作(和链式存储的插入排序方法一样,取未排序序列的第一个key,在已经排序序列里面找插入位置)
效果:减少记录的移动次数。
表插入排序和直接插入排序的原理一样,也是将待插入的元素插入到一个已经排好序的子序列中。不过这里待排序的记录不是放在一个数组结构中而是放在一个静态链表中。插入过程中没有记录的移动,而只有静态链表节点的指针值的变化。但是关键字的比较的数量级和直接插入排序是一样的,因此表插入排序的时间复杂度还是O(n^2)。
为了插入操作的方便这里引入了一个额外的记录,它的关键字是所有可能的待插入的记录的关键字中最大的并且这里的静态链表是循环链表。因此该关键字最大的记录的next值永远指向链表的第一个记录。
希尔排序(不稳定排序)
- 直接插入排序在待排序列的关键字基本有序时,效率较高
- 在待排序的记录个数较少时,效率较高
算法思想:
先选定一个记录下标的增量d,将整个记录序列按增量d从第一个记录开始划分为若干组:
第一组为:(1,1+d, 1+2*d, …),
第二组为:(2,2+d, 2+2*d, …)
第d组为: (d,2d, 3d, …)
对每组使用直接插入排序的方法进行排序;
(单个序列从头开始,每一次添加一个序列中的下一个元素进行直接插入排序)
之后减少d,不断重复上述过程直到d=1
1 | void ShellSortN (SqList &L, int dlta[], int t) |
交换排序
冒泡排序
每趟结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素;
一旦此趟没有交换,可提前结束排序
[算法的改进]
每趟排序中,记录最后一次发生交换的位置
例:{54,32,16,55,103,727,834,1006}
双向交替扫描,改进数据不对称性:
上->下,最重沉底;下->上,最轻升顶。
例:{12,18,42,44,45,67,94,10}
快速排序(随机排列时效率最高)
[算法思想]
指定枢轴/支点/基准记录r[p],通过一趟排序将其放在正确的位置上,它把待排记录分割为独立的两部分,使得
左边记录的关键字 <=r[p].key<=右边记录的关键字
对左右两部分记录序列重复上述过程,依次类推,直到子序列中只剩下一个记录或不含记录为止。(可以用递归方法实现)
1 | int Partition ( SqList &L,int low, int high ) |
选择排序
[算法思想]
每次从待排序列中选出关键字最小记录作为有序序列中最后一个记录,直至最后一个记录为止。
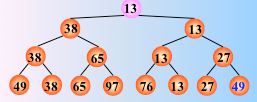
树形选择排序
树形选择排序(Tree Selection Sort),又称锦标赛排序(Tournament Sort),是一种按锦标赛的思想进行选择排序的方法。简单选择排序花费的时间主要在比较上,每次都会进行很多重复的比较,造成浪费时间。锦标赛排序就是通过记录比较结果,减少比较次数,从而降低时间复杂度。
首先对n个记录的关键字进行两两比较,然后再对胜者进行两两比较,如此重复,直至选出最小关键字的记录为止。这个过程可用一棵有n个叶子结点的完全二叉树描述。
对下图数据(胜者树)

堆排序
利用树的结构特征来描述堆,所以树只是作为堆的描述工具,堆实际是存放在线形空间中的。
算法思想:
- 输入数组并建立小顶堆,此时最小元素位于堆顶。
- 不断执行出堆操作,依次记录出堆元素,即可得到从小到大排序的序列。z
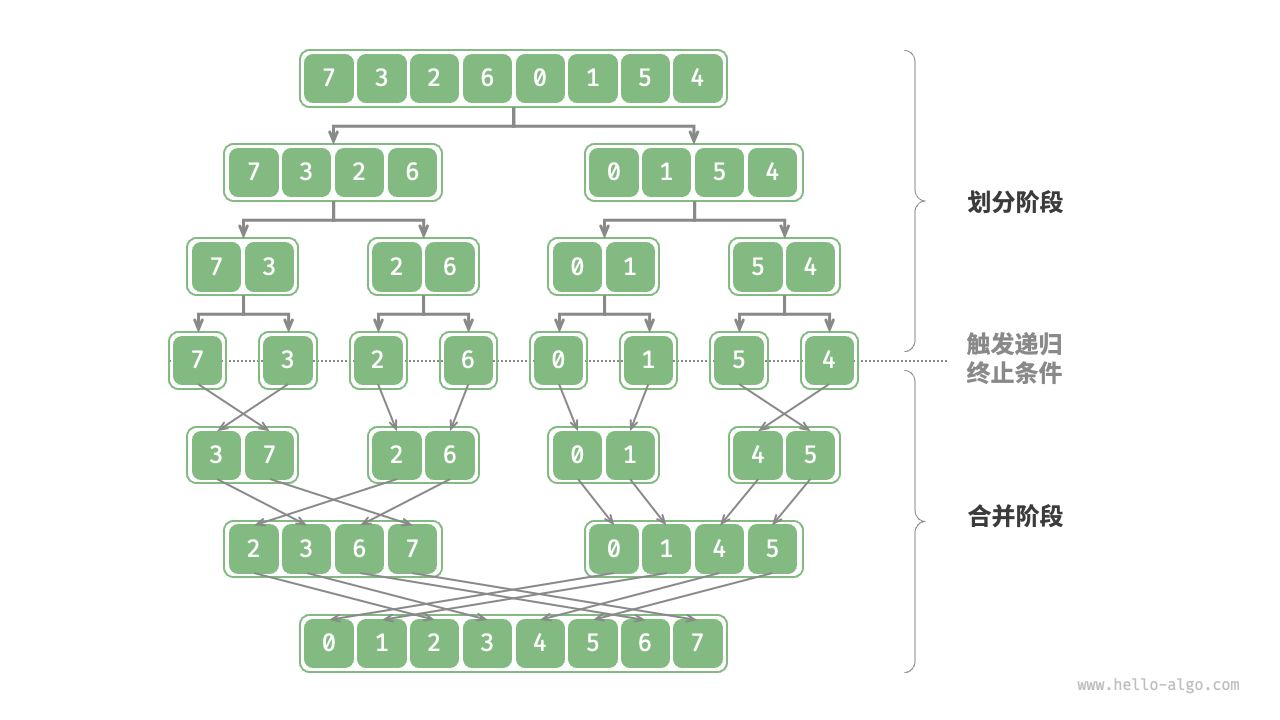
归并排序
将两个或两个以上的同序序列归并成一个序列的操作。
主要包含两个阶段:
- 划分阶段 :通过递归不断地将数组从中点处分开,将长数组的排序问题转换为短数组的排序问题。
- 合并阶段 :当子数组长度为 1 时终止划分,开始合并,持续地将左右两个较短的有序数组合并为一个较长的有序数组,直至结束。
1 | /* 合并左子数组和右子数组 */ |
自然归并算法
自然归并算法实际上是归并算法的一个变型。
例如在下文实例代码中的数组a中的元素为{6,1,9,4,5,8,7,2,3},在数组中的自然排序为{6},{1,9},{4,5,8},{7},{2,3}。接着根据自然排序将相邻的排好序的子数组进行归并排序,这就是自然归并排序算法的基本思想。
通常情况下,自然归并算法需要合并的次数比归并算法要少,而在极端情况下,如:对于已经排好序的n元数组。自然归并算法无需归并操作,算法时间复杂为O(n),而归并算法则需执行logn次合并操作,算法时间复杂度为O(nlogn)。
基数排序(分配排序)
基数排序(radix sort)的核心思想与计数排序一致,也通过统计个数来实现排序。在此基础上,基数排序利用数字各位之间的递进关系,依次对每一位进行排序,从而得到最终的排序结果。
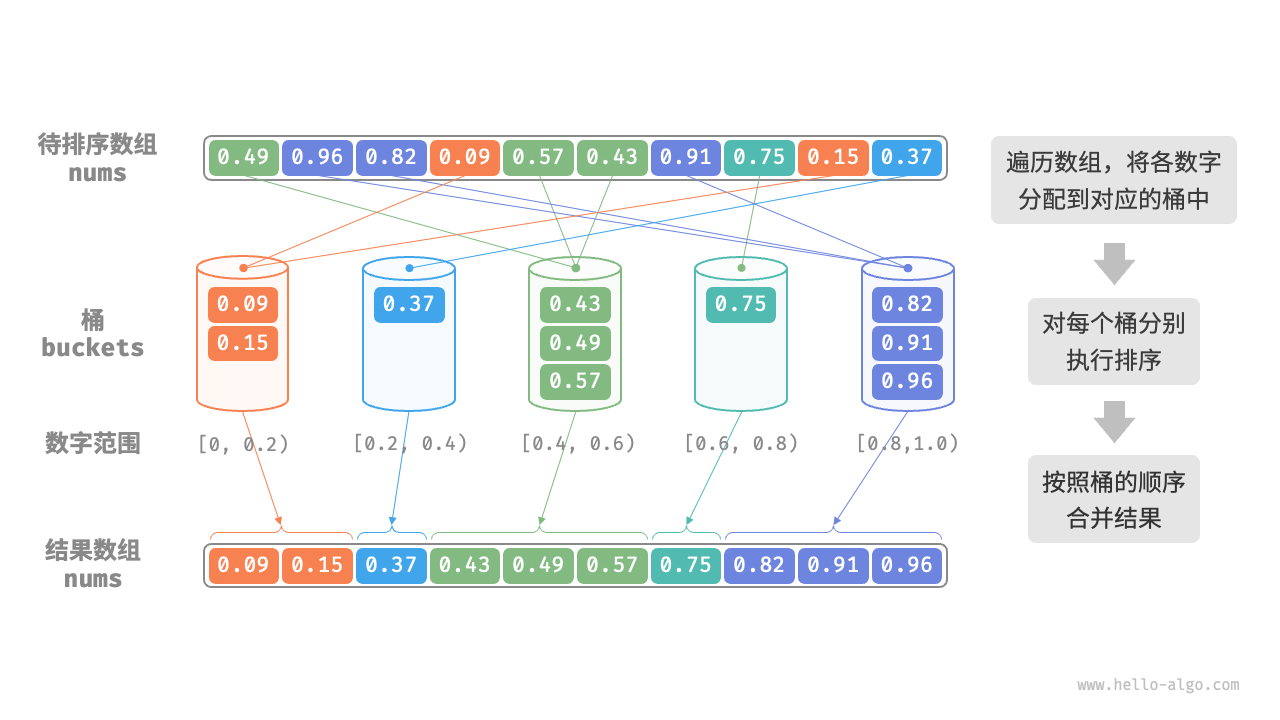
首先我们引入区分一下计数排序和桶排序:
桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序),最后依次把各个桶中的记录列出来记得到有序序列。
计数算法只能使用在已知序列中的元素在0-k之间,并且已知范围
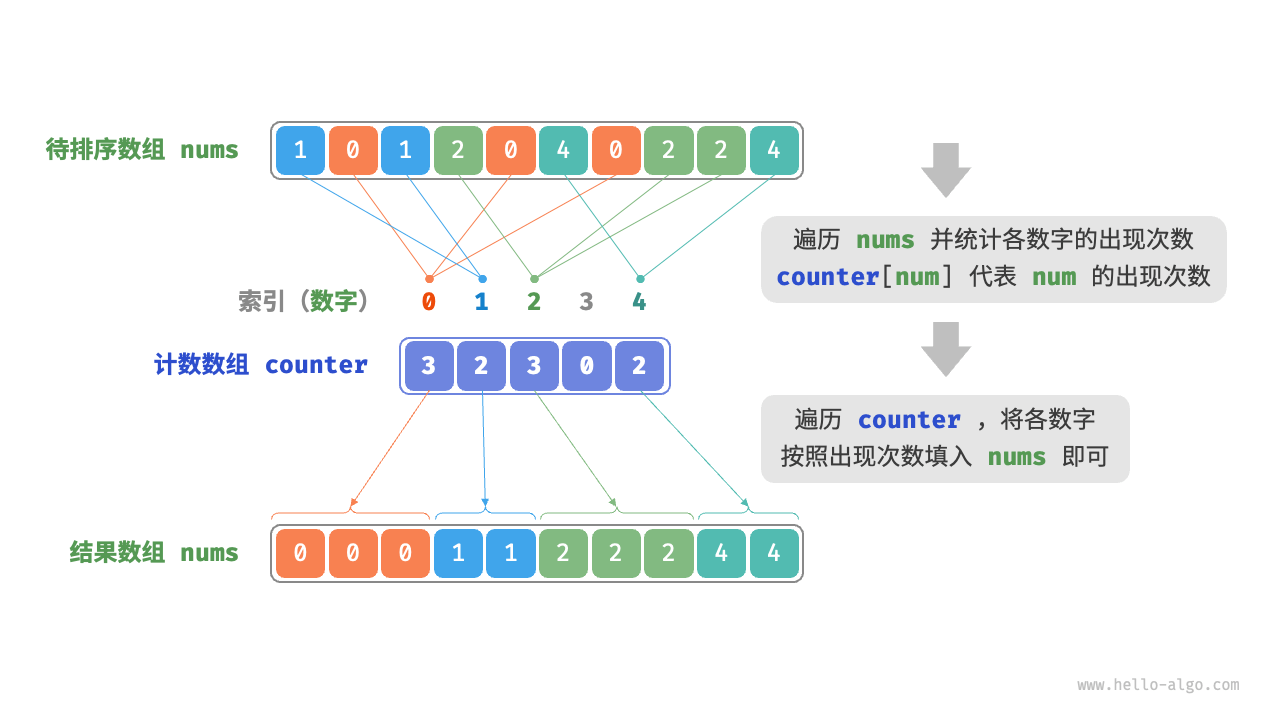
计数排序利用了整数关系划分了更具体的桶,那么基数排序就是在更多位数字时将每一位分别进行类似计数的排序
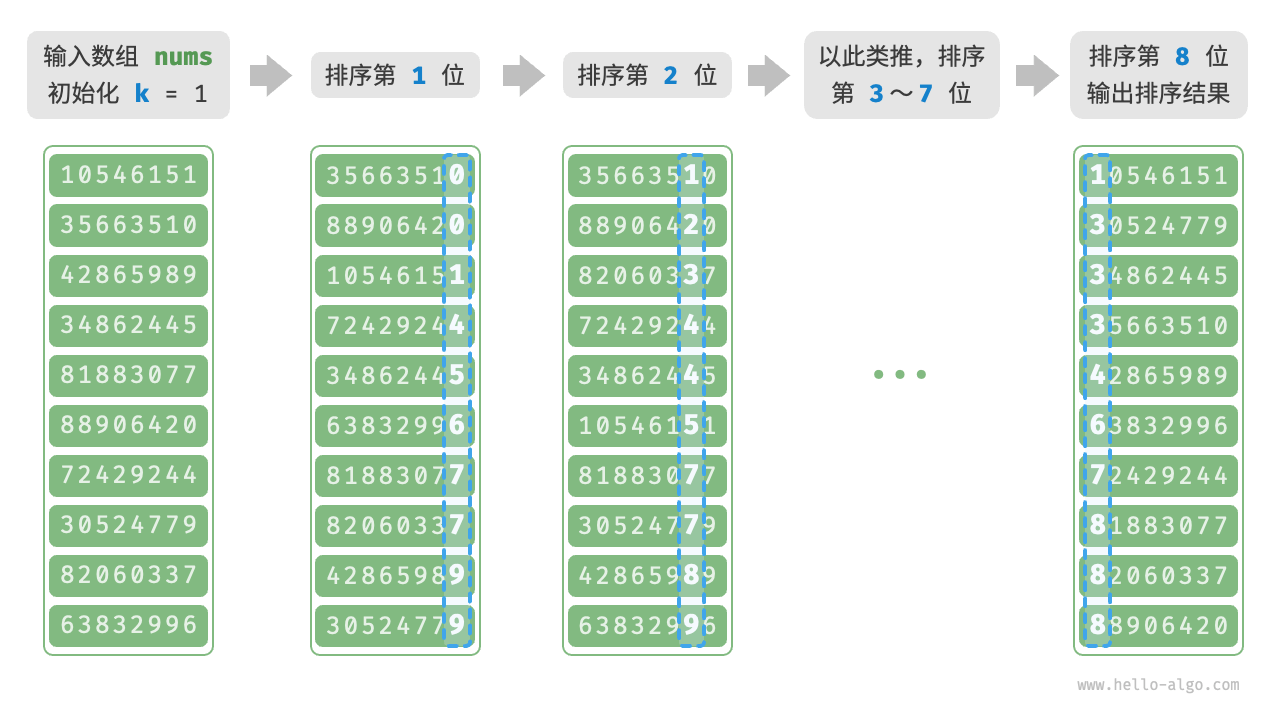
具体实现为从低位开始,每一次分配后收集重新组成数组(其实相当于每一次操作将当前位数排序后放在了[0]这一个位置),直到最后一位

注意基数排序是一个稳定排序
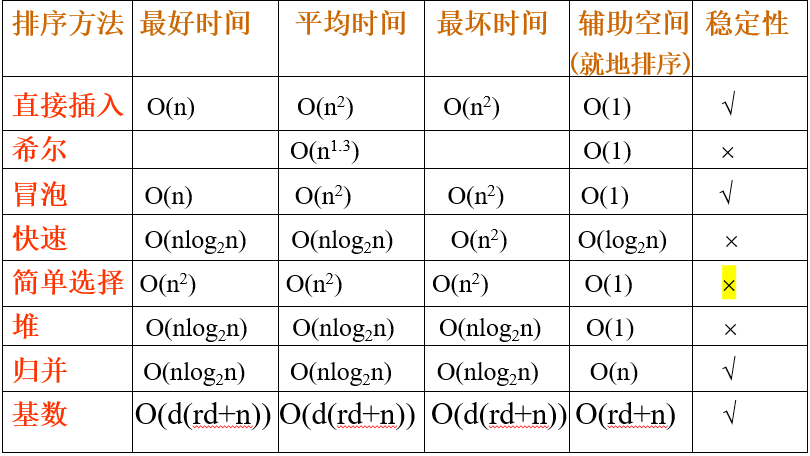
总结
- Title: 内部排序
- Author: time will tell
- Created at : 2024-12-10 10:44:15
- Updated at : 2024-12-15 18:55:21
- Link: https://sbwrn.github.io/2024/12/10/内部排序/
- License: This work is licensed under CC BY-NC-SA 4.0.