
哈希

Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希查找表
根据设定的哈希函数H(key)和处理冲突方法将一组关键字映射到一个有限的地址区间上
即让存储位置与关键字之间存在对应关系 $Loc(i)=H(keyi)$ ,其中H为哈希函数。
详细内容请见Hello算法哈希
术语
- 哈希表:一个有限的连续的地址空间,用以容纳按哈希地址存储的记录。
- 哈希函数:$Loc(ri)=H(keyi)$ 记录的存储位置与它的关键字之间存在的一种对应关系。
- 冲突:对于$keyi != keyj$ , 且$ i != j$
但是出现$H(keyi) = H(keyj)$
虽然$H(keyi) != H(keyj)$,但$keyi$在哈希表中占用了$keyj$的存储位置。 - 同义词:keyi != keyj 但 H(Keyi)和 H(keyj) 相同
- 哈希(散列)地址:根据设定的哈希函数H(key)和处理冲突的方法确定的记录的存储位置。
- 装填因子:表中填入的记录数n和哈希表表长 m之比。
a=n/m
哈希的查找
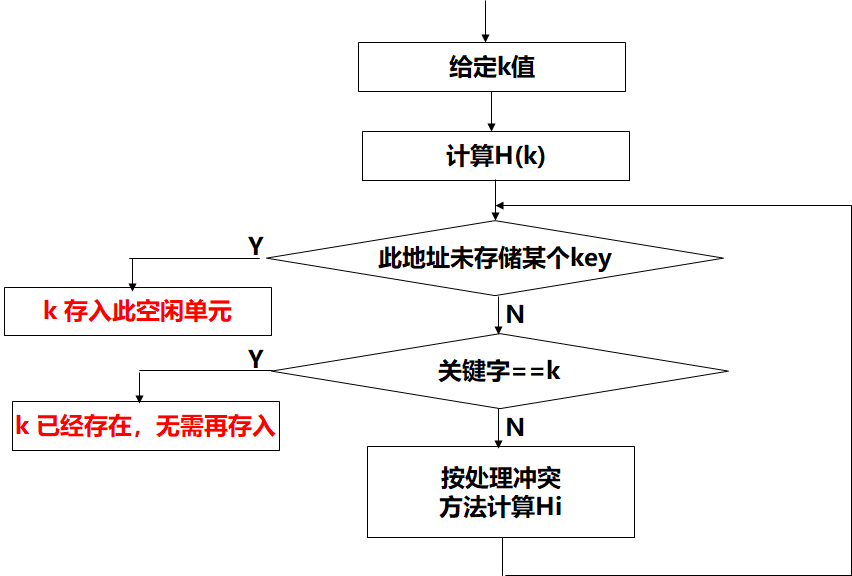
哈希计算得到地址后,取地址内的值与关键字比较;冲突后处理冲突得到新的地址,重复上述过程。
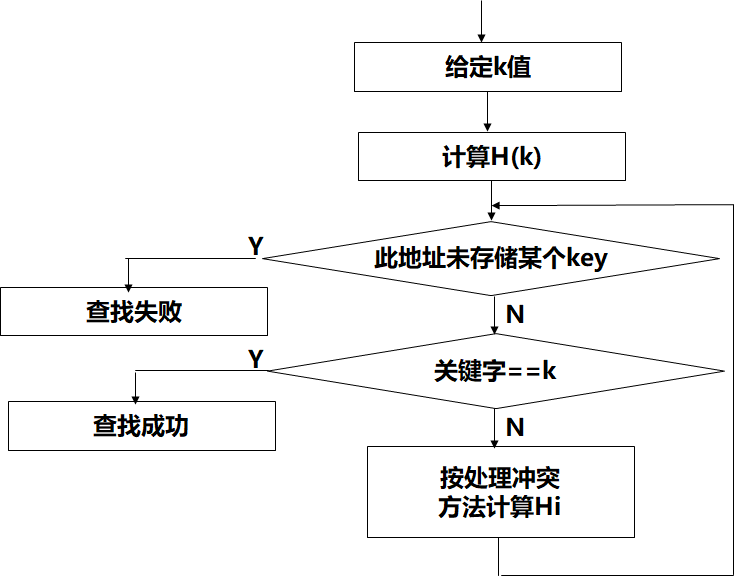
哈希表的建立
直接定址法
$$
H(key)=a*key + b
$$
计算简单,冲突最少
但仅适合于:地址集合的大小= = 关键字集合的大小
数字分析法
取关键字的若干数位作为哈希地址
对每个关键字都是由 s 位数字组成的全体,从中提取分布均匀的若干位或它们的组合作为地址。
仅适合于:能预先估计出全体关键字的每一位上各种数字出现的频度。
平方取中法
取关键字平方后的中间几位作为哈希地址
此方法适合于: 关键字中的每一位都有某些数字重复出现频度很高的现象。
折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几个部分的叠加和(舍去进位)作为哈希地址
此方法适合于: 关键字的数字位数特别多。
除留余数法
H(key) = key MOD p (p: 最好为素数 ,更有利于“散列”)
p的限制目的是减少冲突的可能
(伪)随机数法
H(key) = random(key)
选取一个用关键字作为种子的伪随机数发生器生成散列地址
适合于:关键字长度不等时的情况
处理冲突
开放定址法(空缺编址法)
Hi = ( H(key)+di ) MOD m
其中i=1,2, …, k (k<=m-1) , m: 哈希表的表长; di: 增量序列
根据增量序列为下一个冲突寻找直接地址
求增量序列有如下方法:
- 线性探测:di=1,2,… ,m-1
缺点:出现堆积现象–非同义地址冲突。存取时,可能不是同义词的词也位于探查序列,影响效率。 - 二次探测:即di=i^2 (i<=m/2)
缺点:不易探查到整个散列空间 - 伪随机探测再散列:di = 伪随机数序列
再哈希法
利用准备的一组哈希函数,再下一次冲突发生时,依次使用这一组函数中的下一个来再次计算哈希值,直到冲突不发生为止。
链地址法
为每个哈希地址建立一个单链表,存储所有具有同义词的记录。
建立公共溢出区法
哈希表的建立、查找及其ASL分析

在一般情况下,a上升,冲突的可能性下降,ASL下降,但空间的浪费上升
| 成功ASL | 失败ASL | |
|---|---|---|
| 线性探测再散列 | 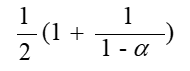 |
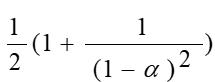 |
| 伪随机探测再散列 | 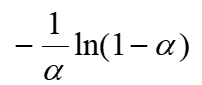 |
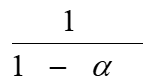 |
| 链地址法 | 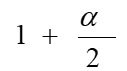 |
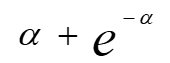 |
- Title: 哈希
- Author: time will tell
- Created at : 2024-12-02 09:13:42
- Updated at : 2024-12-08 15:03:57
- Link: https://sbwrn.github.io/2024/12/02/哈希/
- License: This work is licensed under CC BY-NC-SA 4.0.