动态查找表 频繁进行插入、删除的查找表
二叉排序树BST 定义 安装左中右的顺序排序,左子树上所有结点的值均小于根结点的值,右子树上所有结点的值均大于根结点的值
中序遍历一棵二叉排序树,将得到一个以关键字递增排列的有序序列
操作 查找 查找就是从根节点开始,如果比根节点小就往左子树查找,反之往右子树查找,找到了或者结点为空时停止
非递归形式
1 2 3 4 5 6 7 8 9 10 11 12 Bitree SearchBST ( BiTree T, KeyType key ) { if ( (!T) || EQ(key, T->data.key)) return T; else if ( LT(key, T->data.key)) return (SearchBST(T->lchild, key)); else return (SearchBST(T->rchild, key)); }
递归形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bool SearchBST (BiTree T, KeyType key, BiTree f, BiTree &p) { if (!T) { p=f; return FALSE; } else if EQ(key, T->data.key) { p=T; return TRUE; } else if LT(key, T->data.key) return SearchBST(T->lchild, key, T, p); else return SearchBST(T->rchild, key, T, p); }
链表形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 bool SearchBST (BiTree T, KeyType key, BiTree &p) { BiTree p = T; BiTree q = NULL ; while (p) { if (EQ(key, p->data.key)) return TRUE; q = p; if (LT(key, p->data.key)) p = p->lchild; else p = p->rchild; } p = q; return FALSE; }
插入 插入则是在查找到的那个位置进行判断,一般如果在树中没有该元素时,查找到一个空结点,那么就可以直接插入
实际代码操作有一些不同
非递归形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 bool InsertBST (BiTree &T,ElemType e) { if (!SearchBST(T, e.key, NULL , P)) { s=(BiTree)malloc (sizeof (BiTNode)); s->data=e; s->lchild=s->rchild=NULL ; if (!T) T=s; else if LT(e.key, p->data.key) p->lchild = s; else p->rchild = s; return TRUE; } else return FALSE }
这里用到了查找的递归形式,函数会在查找函数中没有找到该元素时先修改p结点为需要插入的上一个结点,然后再将p结点与需要插入的值进行判断,将其插入到左结点还是右结点
一步到位的形式为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Status SearchBST (BiTree &T, KeyType key, BiTree &p) { p = T; Bitree q=NULL ; while (p) { if (EQ(key, p->data.key)) { return OK; } q=p; if (LT(key, p->data.key)) { p = p->lchild;} else {p = p->rchild; } } if (!(p = (BiTree)malloc (sizeof (BiTNode))) return OVERSTACK; p->data=key; p->lchild=p->rchild=NULL ; if (!T) T = p; else if (LT(key, q->data)) q->lchild = p; else q->rchild = p; return OK; }
同理,递归形式如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Status SearchInsertBST (BiTree T, BiTree f, KeyType key, BiTree &p) { if (!T) { if (!(p = (BiTree)malloc (sizeof (BiTNode)))) return OVERSTACK; p->data=key; p->lchild=s->rchild=NULL ; if LT (key, f->data.key) f->lchild = p; else f->rchild = p; return OK; } else if EQ(key, T->data.key){ p=T; return OK; } else if LT(key, T->data.key) return SearchInsertBST(T->lchild, T, key, p); else return SearchInsertBST(T->rchild, T, key, p); }
删除 删除结点被分为4种情况
p是叶子结点:修改其双亲指针指向NULL即可
p只有左孩子:用p的左子树代替以p为根的子树
p只有右孩子:用p的右子树代替以p为根的子树
p有两个孩子:找到p的中序后继(或前趋)结点q,q的数据复制给p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 Status DeleteBST (BiTree &T, KeyType key) { if (T == NULL ) return ERROR; if (LT(key, T->data)) { return DeleteBST(T->lchild, key); } else if (LT(T->data, key)) { return DeleteBST(T->rchild, key); } else { if (T->lchild != NULL && T->rchild != NULL ) { BiTree temp = FindMin(T->rchild); T->data = temp->data; return DeleteBST(T->rchild, temp->data); } else { BiTree temp = T; if (T->lchild == NULL ) { T = T->rchild; } else if (T->rchild == NULL ) { T = T->lchild; } free (temp); return OK; } } } BiTree FindMin (BiTree T) { if (T == NULL ) return NULL ; while (T->lchild != NULL ) { T = T->lchild; } return T; }
平衡二叉树(AVL树) 关键字有序出现时,将构造出“退化”的二叉排序树,这使得查找的效率降低,为避免这种情况发生,需要采用平衡二叉树
定义 空树,或者是满足如下性质的二叉排序树:
左、右子树的高度之差的绝对值不超过1
左右子树本身又各是一棵平衡二叉树
引入一个平衡因子 的概念
二叉树上结点的平衡因子:该结点的左子树高度减去右子树的高度
但是不得不承认,平衡二叉树不一定是理想的最矮状态
查找的分析 一个具有n个结点的平衡二叉树的最大深度h为
$$
其中a
$$
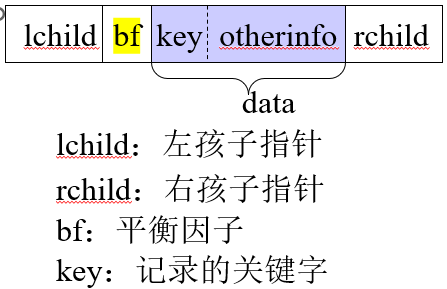
结点的存储结构
1 2 3 4 5 6 7 8 9 10 11 typedef struct { KeyType key; …… }ElemType typedef struct BSTNode { ElemType data; int bf; struct BSTNode *lchild , *rchild ; }BSTNode, * BSTree;
平衡二叉树上的操作 1、结点高度 结构中已经确认添加了结点高度height,对于每个结点都有如下定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 typedef struct TreeNode { int val; int height; struct TreeNode *left ; struct TreeNode *right ; } TreeNode; TreeNode *newTreeNode (int val) { TreeNode *node; node = (TreeNode *)malloc (sizeof (TreeNode)); node->val = val; node->height = 0 ; node->left = NULL ; node->right = NULL ; return node; }
“节点高度”是指从该节点到它的最远叶节点的距离,即所经过的“边”的数量。需要特别注意的是,叶节点的高度为 0 ,而空节点的高度为 −1 。我们将创建两个工具函数,分别用于获取和更新节点的高度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int height (TreeNode *node) { if (node != NULL ) { return node->height; } return -1 ; } void updateHeight (TreeNode *node) { int lh = height(node->left); int rh = height(node->right); if (lh > rh) { node->height = lh + 1 ; } else { node->height = rh + 1 ; } }
2、结点平衡因子 设平衡因子为 f ,则一棵 AVL 树的任意节点的平衡因子皆满足 −1≤f≤1 。
节点的平衡因子(balance factor)定义为节点左子树的高度减去右子树的高度,同时规定空节点的平衡因子为 0 。我们同样将获取节点平衡因子的功能封装成函数,方便后续使用:
1 2 3 4 5 6 7 8 9 int balanceFactor (TreeNode *node) { if (node == NULL ) { return 0 ; } return height(node->left) - height(node->right); }
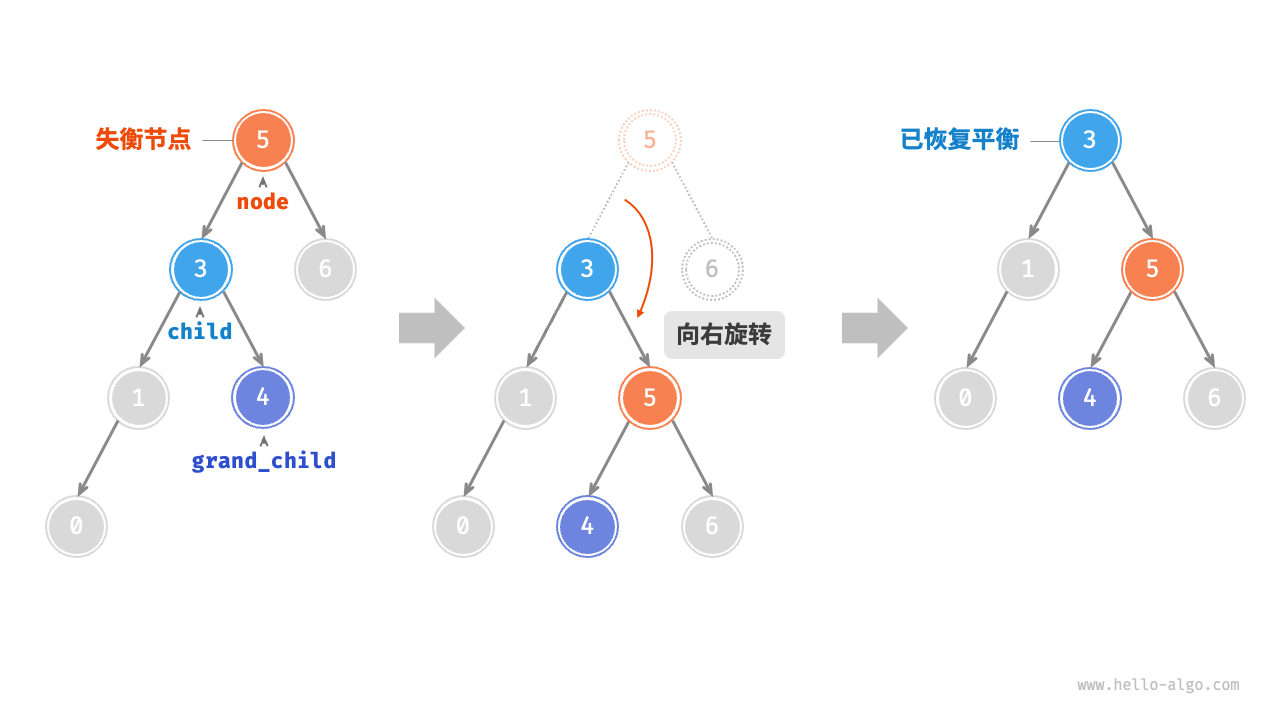
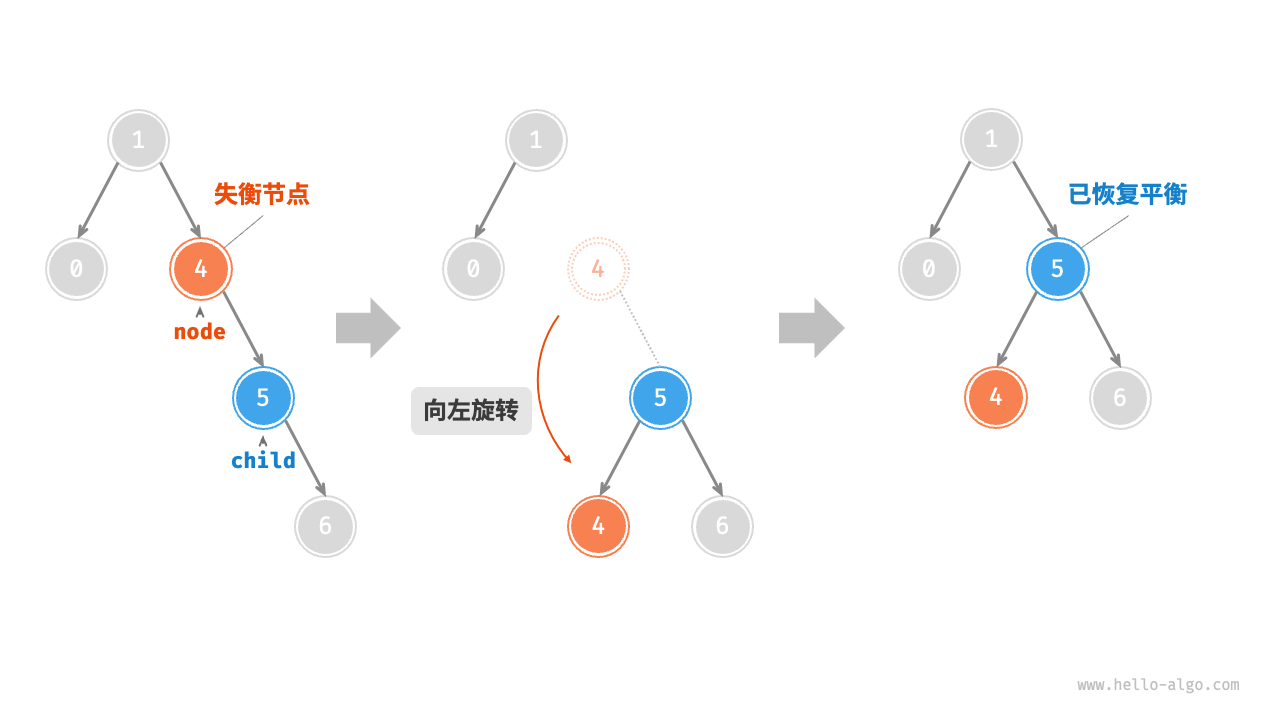
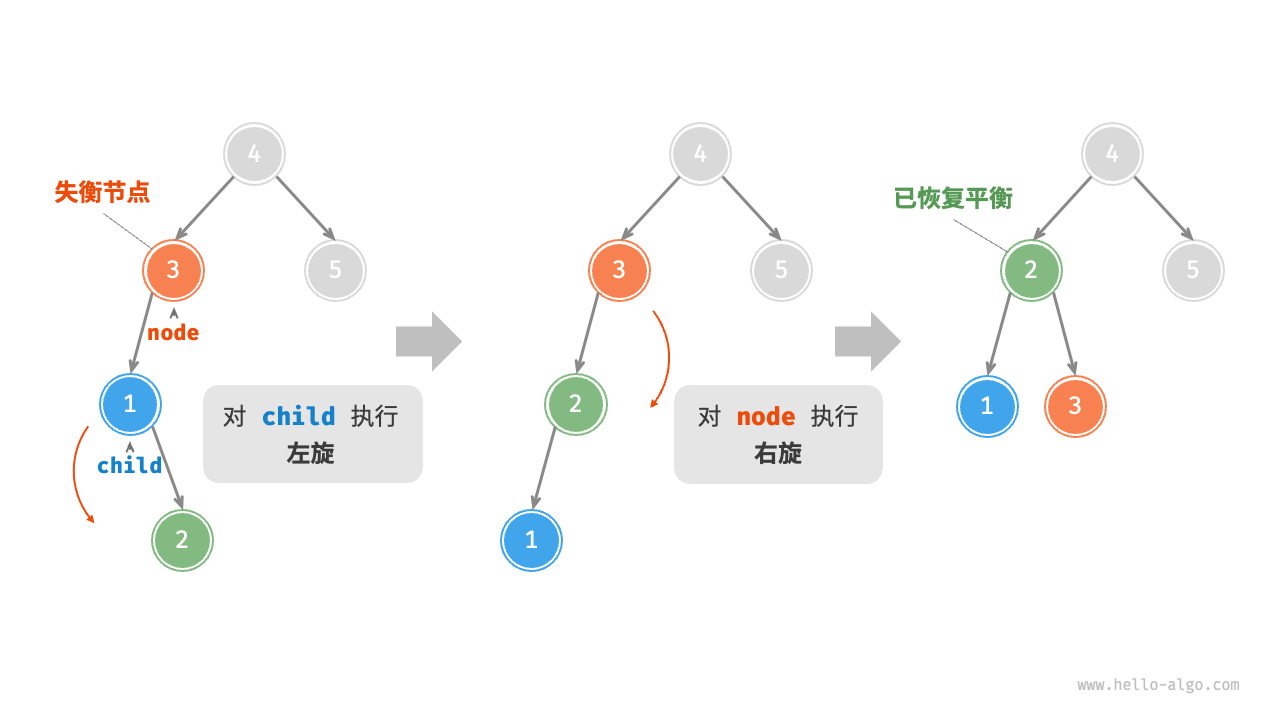
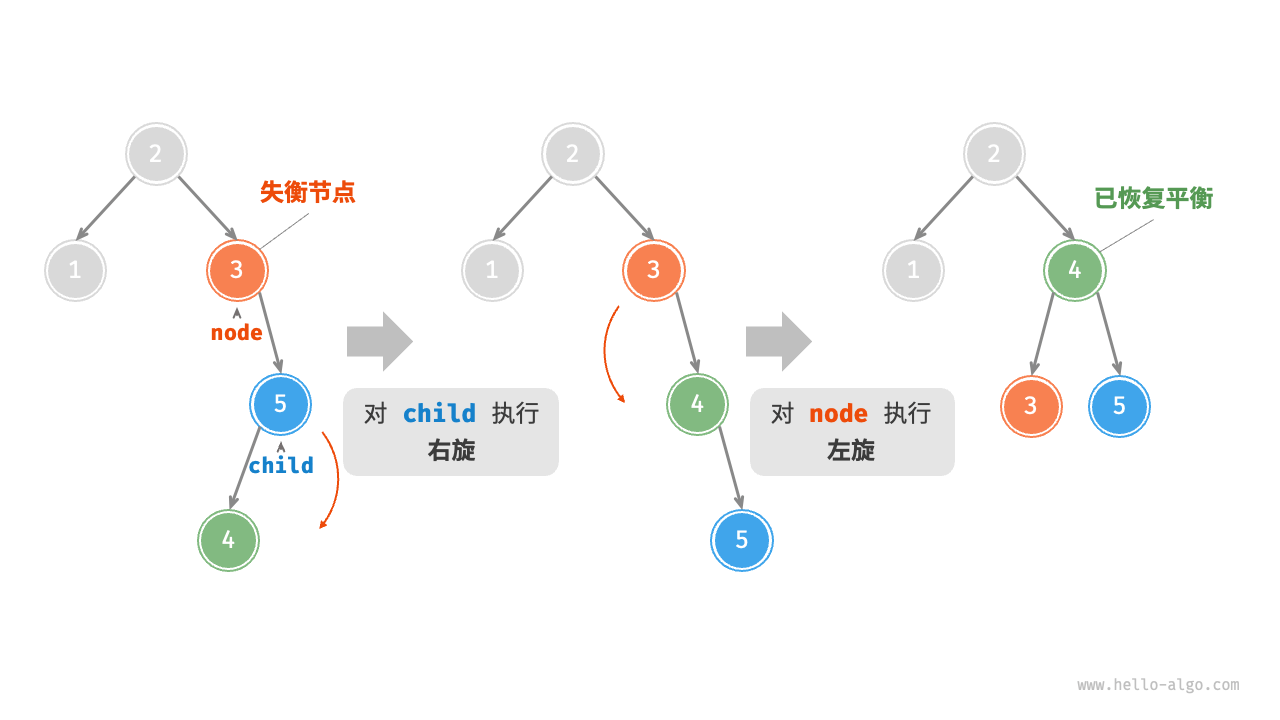
AVL树旋转 在不影响二叉树的中序遍历序列的前提下,使失衡节点重新恢复平衡。
将平衡因子绝对值 >1 的节点称为“失衡节点” 。根据节点失衡情况的不同,旋转操作分为四种:右旋、左旋、先右旋后左旋、先左旋后右旋。
1、右旋
1 2 3 4 5 6 7 8 9 10 11 12 13 14 TreeNode *rightRotate (TreeNode *node) { TreeNode *child, *grandChild; child = node->left; grandChild = child->right; child->right = node; node->left = grandChild; updateHeight(node); updateHeight(child); return child; }
2、左旋 相应地考虑镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 TreeNode *leftRotate (TreeNode *node) { TreeNode *child, *grandChild; child = node->right; grandChild = child->left; child->left = node; node->right = grandChild; updateHeight(node); updateHeight(child); return child; }
3、先左旋再右旋
4、先右旋后左旋
5、旋转选择 如下表所示,我们通过判断失衡节点的平衡因子以及较高一侧子节点的平衡因子的正负号,来确定失衡节点属于哪种情况
失衡节点的平衡因子
子节点的平衡因子
应采用的旋转方法
>1左偏树
>=0
右旋
>1左偏树
<0
先左旋后右旋
<-1右偏树
<=0
左旋
<-1右偏树
>0
先右旋后左旋
将以上规律封装成函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 TreeNode *rotate (TreeNode *node) { int bf = balanceFactor(node); if (bf > 1 ) { if (balanceFactor(node->left) >= 0 ) { return rightRotate(node); } else { node->left = leftRotate(node->left); return rightRotate(node); } } if (bf < -1 ) { if (balanceFactor(node->right) <= 0 ) { return leftRotate(node); } else { node->right = rightRotate(node->right); return leftRotate(node); } } return node; }
插入与删除操作 在 AVL 树中插入节点后,从该节点到根节点的路径上可能会出现一系列失衡节点。因此, 我们需要从这个节点开始,自底向上执行旋转操作,使所有失衡节点恢复平衡 。(递归形式恢复)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void insert (AVLTree *tree, int val) { tree->root = insertHelper(tree->root, val); } TreeNode *insertHelper (TreeNode *node, int val) { if (node == NULL ) { return newTreeNode(val); } if (val < node->val) { node->left = insertHelper(node->left, val); } else if (val > node->val) { node->right = insertHelper(node->right, val); } else { return node; } updateHeight(node); node = rotate(node); return node; }
删除同理,也是从底至顶地进行旋转操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void removeItem (AVLTree *tree, int val) { TreeNode *root = removeHelper(tree->root, val); } TreeNode *removeHelper (TreeNode *node, int val) { TreeNode *child, *grandChild; if (node == NULL ) { return NULL ; } if (val < node->val) { node->left = removeHelper(node->left, val); } else if (val > node->val) { node->right = removeHelper(node->right, val); } else { if (node->left == NULL || node->right == NULL ) { child = node->left; if (node->right != NULL ) { child = node->right; } if (child == NULL ) { return NULL ; } else { node = child; } } else { TreeNode *temp = node->right; while (temp->left != NULL ) { temp = temp->left; } int tempVal = temp->val; node->right = removeHelper(node->right, temp->val); node->val = tempVal; } } updateHeight(node); node = rotate(node); return node; }
红黑树 红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能
它的左右子树高差有可能大于1,所以红黑树不是严格意义上的平衡二叉树(AVL),但对之进行平衡的代价较低, 其平均统计性能要强于 AVL
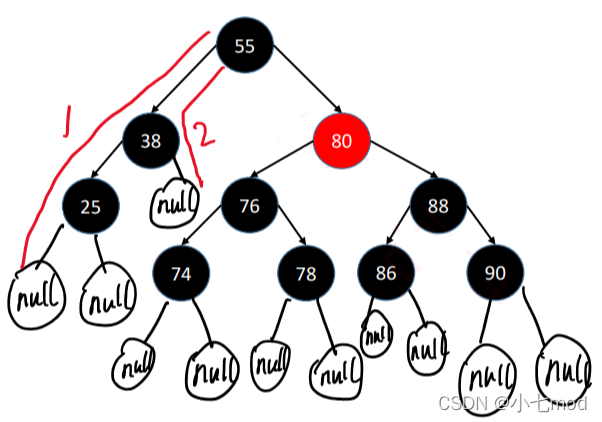
特征 红黑树是每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色
根节点是黑色
叶子节点(外部节点,空节点)都是 黑色, 这里的叶子节点指的是最底层的空节点(外部节点),下图中的那些null节点才是叶子节点,null节点的父节点在红黑树里不将其看作叶子节点
每个红色节点的两个子节点都是黑色(从每个叶子到根的所有路径上不能有两个连续的红色节点)
每个红色结点的父节点都是黑色
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
从根到叶子的最长的可能路径不多于最短的可能路径的两倍长
红黑树因而近似平衡(最短路径就是全黑节点,最长路径就是一个红节点一个黑节点,当从根节点到叶子节点的路径上黑色节点相同时,最长路径刚好是最短路径的两倍)
真正被定义为叶子结点的是那些空结点
查找操作时 ,它和普通的相对平衡的二叉搜索树的效率相同,都是通过相同的方式来查找的,没有用到红黑树特有的特性。
但如果插入的时候 是有序数据,那么红黑树的查询效率就比二叉搜索树要高了,因为此时二叉搜索树不是平衡树,它的时间复杂度O(N)。
插入和删除操作 插入和删除操作 时,由于红黑树的每次操作平均要旋转一次和变换颜色,所以它比普通的二叉搜索树效率要低一点,不过时间复杂度仍然是O(logN)。总之,红黑树的优点就是对有序数据的查询操作不会慢到O(logN)的时间复杂度。
插入时将插入的结点设置为红色,只需要考虑连续红色的情况
总结 利用对树中的结点“红黑着色”的要求,降低了平衡性的条件,达到局部平衡,有着良好的最坏情况运行时间,它可以在O(log n)时间内做查找,插入和删除,这里的n是树中元素的数目。
B-树 B 树(B-tree)是一种自平衡的搜索树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。B 树的每个节点可以拥有两个以上的子节点,因此 B 树是一种多路搜索树。
在 B 树中,有两种节点:
内部节点(internal node):存储了数据以及指向其子节点的指针。
叶子节点(leaf node):与内部节点不同的是,叶子节点只存储数据,并没有子节点。
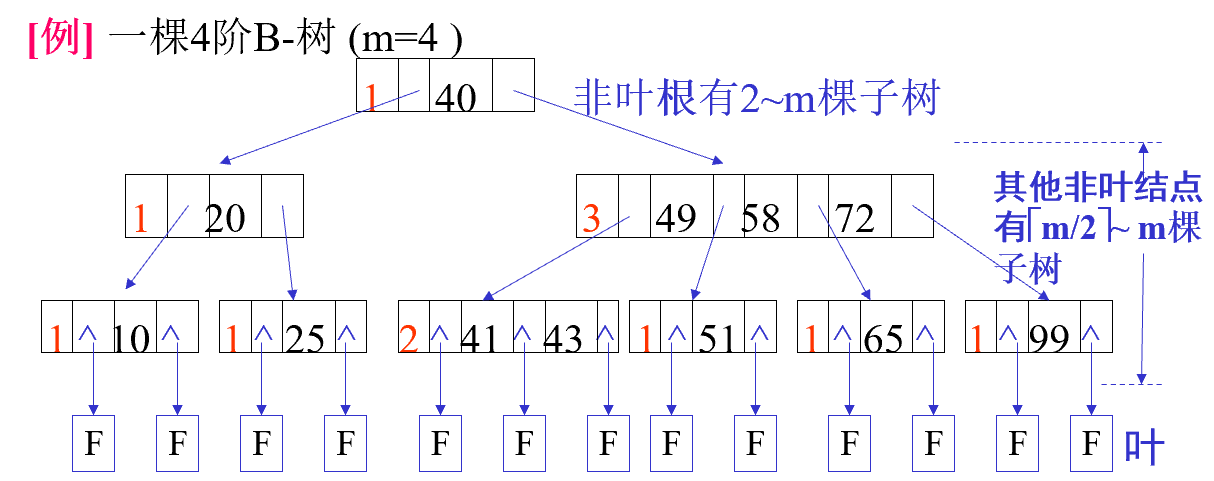
性质 一棵 m 阶的 B 树满足的性质如下:
树中每个结点最多有m棵子树
若根结点不是叶子结点,则最少有两棵子树
除根之外的所有非叶子结点最少有[m/2]棵子树
所有非叶子结点包含 (n,A0,K1,A1,K2,…,Kn,An)信息数据;其中n为结点中关键字个数,Ai为指向子树的指针,Ki为关键字
所有叶子结点在同一层上,且不带信息
每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)
其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。
Ai(0≤i≤n)为指向子树根结点的指针。
且Ai所指子树所有结点中的关键字均小于Ki+1。
n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
结构定义 1 2 3 4 5 6 7 8 9 10 B-树节点定义 #define m 3 typedef struct BTNode { int keynum; struct BTNode *parent ; KeyType key[m+1 ]; struct BTNode *ptr [m +1]; Record *recptr[m+1 ]; } BTNode, *BTree;
查找
在当前结点*p中顺序或者折半查找若找到某个i,满足key[i]=K,则查找成功,返回p、i、1;
若*p结点中的ptr[i]为空指针,则查找失败,返回p、i、0
从磁盘上读入ptr[i]指示的结点 DiskRead(p->ptr[i]),将此结点作为当前结点,转(1)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Result SearchBTree (BTree T, KeyType K) { p = T; q = NULL ; found = FALSE; i=0 ; while (p && ! found) { i = Search(p, K); if ( i>0 && p->key[i]==K ) found = TRUE; else { q = p; p = p->ptr[i]; } } if (found) return (p,i,1 ); else return (q,i,0 ); }
插入
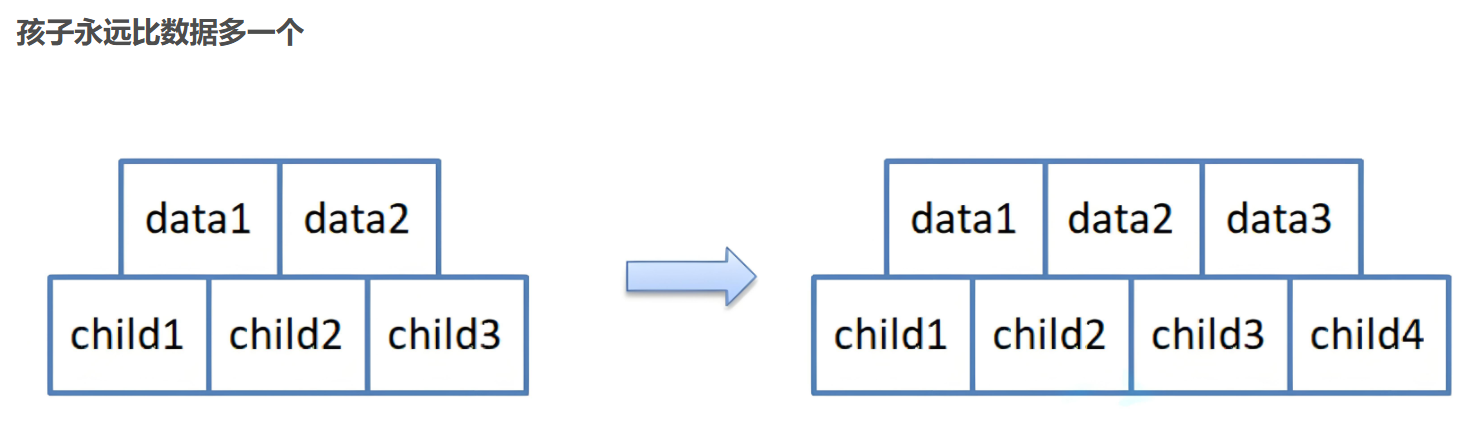
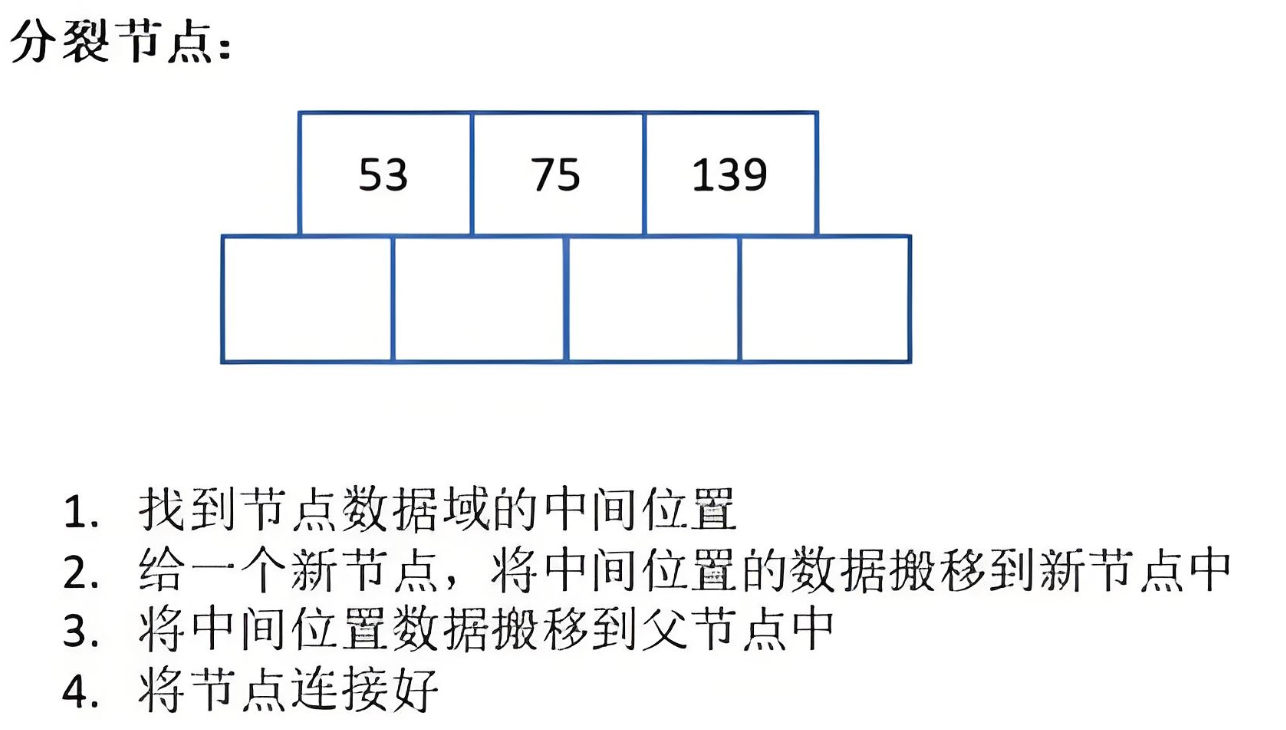
如果叶子节点空间足够,即该节点的关键字数小于 m-1,则直接插入在叶子节点的左边或右边;
如果空间满了以至于没有足够的空间去添加新的元素,即该节点的关键字数已经有了 m个,则需要将该节点进行「分裂」,将一半数量的关键字元素分裂到新的其相邻右节点中,中间关键字元素上移到父节点中,而且当节点中关键元素向右移动了,相关的指针也需要向右移。
从该节点的原有元素和新的元素中选择出中位数
小于这一中位数的元素放入左边节点,大于这一中位数的元素放入右边节点,中位数作为分隔值。
分隔值被插入到父节点中,这可能会造成父节点分裂,分裂父节点时可能又会使它的父节点分裂,以此类推。如果没有父节点(这一节点是根节点),就创建一个新的根节点(增加了树的高度)。
如果一直分裂到根节点,那么就需要创建一个新的根节点。它有一个分隔值和两个子节点。
第一个关键字的插入也是从空树开始。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 void BTree::insert (int k) { if (root == NULL ) { root = new BTreeNode(t, true ); root->keys[0 ] = k; root->n = 1 ; } else { if (root->n == 2 * t - 1 ) { BTreeNode *s = new BTreeNode(t, false ); s->C[0 ] = root; s->splitChild(0 , root); int i = 0 ; if (s->keys[0 ] < k) i++; s->C[i]->insertNonFull(k); root = s; } else root->insertNonFull(k); } } void BTreeNode::insertNonFull (int k) { int i = n - 1 ; if (leaf == true ) { while (i >= 0 && keys[i] > k) { keys[i + 1 ] = keys[i]; i--; } keys[i + 1 ] = k; n = n + 1 ; } else { while (i >= 0 && keys[i] > k) i--; if (C[i + 1 ]->n == 2 * t - 1 ) { splitChild(i + 1 , C[i + 1 ]); if (keys[i + 1 ] < k) i++; } C[i + 1 ]->insertNonFull(k); } } void BTreeNode::splitChild (int i, BTreeNode *y) { BTreeNode *z = new BTreeNode(y->t, y->leaf); z->n = t - 1 ; for (int j = 0 ; j < t - 1 ; j++) z->keys[j] = y->keys[j + t]; if (y->leaf == false ) { for (int j = 0 ; j < t; j++) z->C[j] = y->C[j + t]; } y->n = t - 1 ; for (int j = n; j >= i + 1 ; j--) C[j + 1 ] = C[j]; C[i + 1 ] = z; for (int j = n - 1 ; j >= i; j--) keys[j + 1 ] = keys[j]; keys[i] = y->keys[t - 1 ]; n = n + 1 ; }
写不下去了参考这个吧Btree
B+树 B+树是B树的变形,是在B树基础上优化的多路平衡搜索树
B+树是一种多叉排序树,即每个节点通常有多个孩子。一棵 B+ 树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
有n棵子树的节点中含有n-1个关键字(即将区间分为n-1个子区间,每个子区间对应一棵子树)\
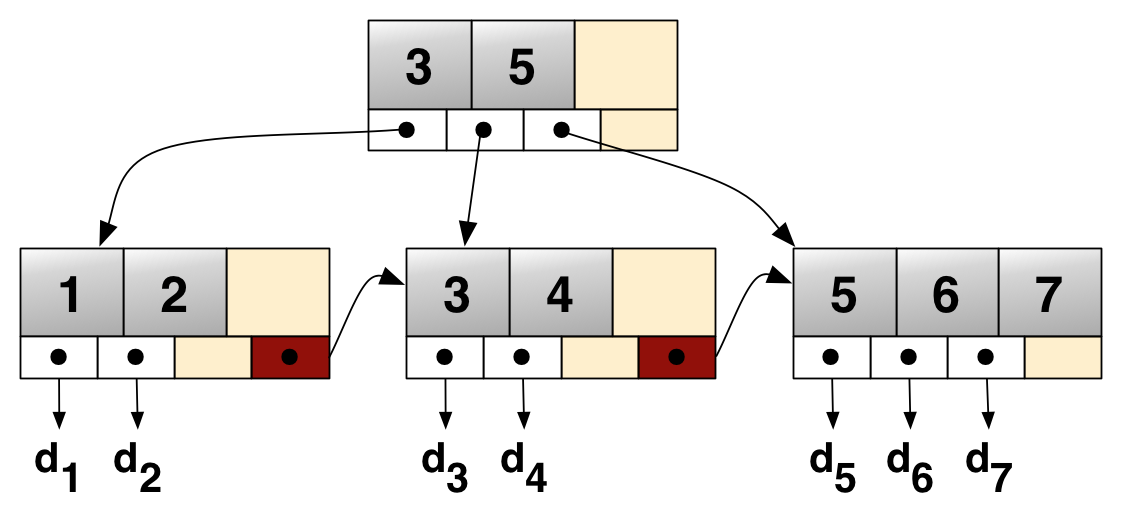
所有叶子节点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接。
所有的非叶子节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字。
除根节点外,其他所有节点中所含关键字的个数最少有「n/2](注意:B 树中除根以外的所有非叶子节点至少有[n/2]棵子树)
分支节点的子树指针与关键字个数相同
分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间
所有叶子节点增加一个链接指针链接在一起
所有关键字及其映射数据都在叶子节点出现
同时,B+ 树为了方便范围查询,叶子节点之间还用指针串联起来。
以下是一棵 B+ 树的典型结构:
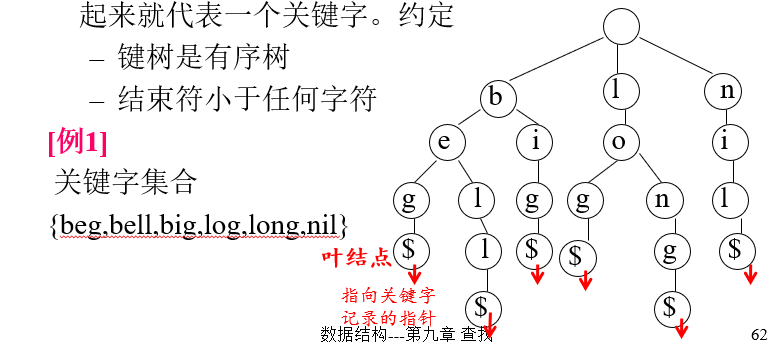
键树 将关键字分解为字符 的多叉树
多叉树中的每个结点只代表关键字中的一个字符
叶结点用于表示字符串的结束符(如‘$’),并含有指向该关键字记录的指针。
而从根到叶子的路径上所有的结点对应的字符连接起来就代表一个关键字。
键树的存储结构及其操作
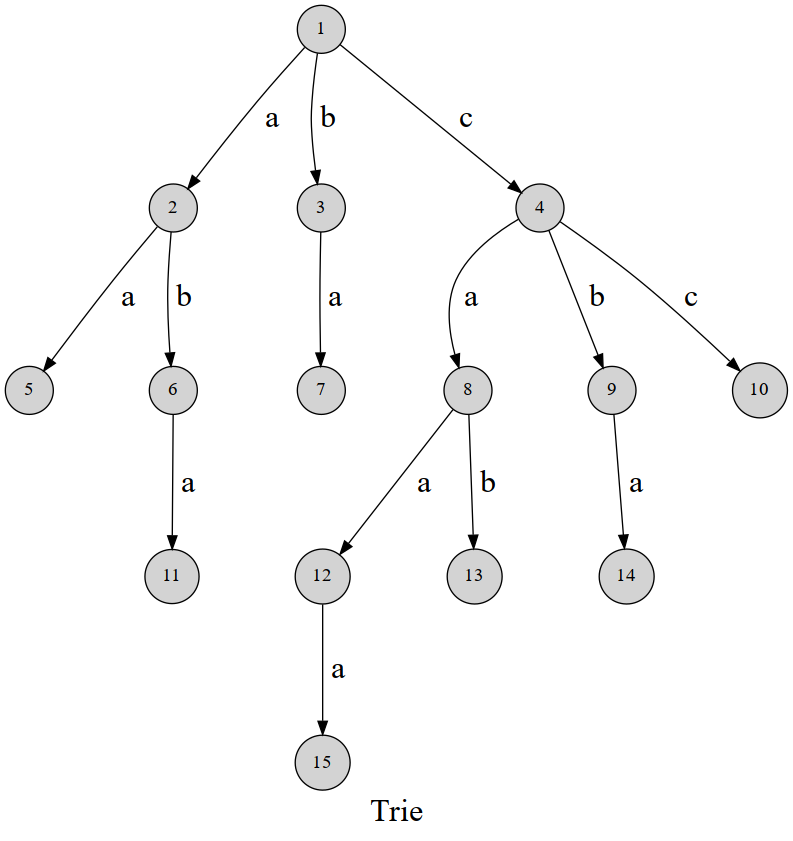
Trie树(字典树)
若从键树中某个结点开始到叶子结点的路径上的每个结点中都只有一个孩子,则将该路径上的所有结点压缩成一个“叶子结点”,且叶子结点中存储有指向记录的指针。
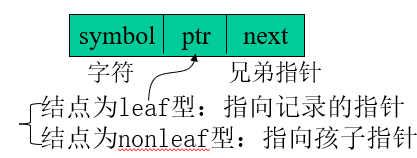
分支结点:num—有用指针的数量
ptr[0..m]—指针数组
叶子结点:key—关键字
recptr—指向对应记录的指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct trie { int nex[100000 ][26 ], cnt; bool exist[100000 ]; void insert (char *s, int l) { int p = 0 ; for (int i = 0 ; i < l; i++) { int c = s[i] - 'a' ; if (!nex[p][c]) nex[p][c] = ++cnt; p = nex[p][c]; } exist[p] = true ; } bool find (char *s, int l) { int p = 0 ; for (int i = 0 ; i < l; i++) { int c = s[i] - 'a' ; if (!nex[p][c]) return 0 ; p = nex[p][c]; } return exist[p]; } };