
树和二叉树

结构概述
逻辑结构
集合——数据元素间除“同属于一个集合”外,无其它关系
如,一堆沙子
线性结构——一个对一个,如线性表、栈、队列
如,一根链条,一个单词中的所有字母
树形结构——一个对多个,如树
如,一棵树,家谱树等
图形结构——多个对多个,如图
如,交通图,高铁图
存储结构
顺序存储结构——
借助元素在存储器中的相对位置
表示数据元素间的逻辑关系(如前后关系),
相对位置可通过计算得到
链式存储结构——
借助指示元素存储地址的指针
表示数据元素间的逻辑关系(如前后关系),
需通过遍历(依次访问)链表得到指定元素的存储位置
树的结构定义
线性结构是指元素之间至多有一个前驱元素或一个后继元素的情况,然而在现实生活中或数学抽象中还有一种情况是元素至多有一个前驱元素,而可有多个后继元素的情况,称之为树结构。
层次结构
树是一类重要的非线性数据结构,是以分支关系定义的层次结构。
树(Tree)是n(n≥0)个结点的有限集,它或为空树(n = 0);或为非空树,对于非空树T:
(1)有且仅有一个称之为根的结点;
(2)除根结点以外的其余结点可分为m(m>0)个互不相交的有限集T1, T2, …, Tm, 其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
树的递归定义刻画了树的固有特性,即一棵非空树是由若干棵子树构成的,而子树又可由若干棵更小的子树构成。
结构特点
树具有下面两个特点:
⑴树的根结点没有前驱结点,除根结点之外的所有结点有且只有一个前驱结点。
⑵树中所有结点可以有零个或多个后继结点。
基本术语
结点的度 结点拥有的子树数目。
叶子(终端)结点 度为0的结点。
分支(非终端)结点 度不为0的结点。
树的度 树的各结点度的最大值。
内部结点 除根结点之外的分支结点。
双亲与孩子(父与子)结点 结点的子树的根称为该结点的孩子;该结点称为孩子的双亲。
兄弟 属于同一双亲的孩子。
结点的祖先 从根到该结点所经分支上的所有结点。
结点的子孙 该结点为根的子树中的任一结点。
二叉树
定义
二叉树(Binary Tree)是n(n≥0)个结点所构成的集合,它或为空树(n = 0);或为非空树,对于非空树T:
(1)有且仅有一个称之为根的结点;
(2)除根结点以外的其余结点分为两个互不相交的子集T1和T2,分别称为T的左子树和右子树,且T1和T2本身又都是二叉树。
引入二叉树是作为一般树(森林)的规范形式,它与树(森林)可以建立一一对应,为解决树的问题提供方便。
二叉树结点的子树要区分左子树和右子树,即使只有一棵子树也要进行区分,说明它是左子树,还是右子树。这是二叉树与普通树的最主要的差别。
满二叉树
如果一棵二叉树每一层的结点个数都达到了最大,这棵二叉树称为满二叉树。对于满二叉树,所有的分支结点都存在左子树和右子树,所有叶子都在最下面一层。一棵深度为k的满二叉树有2^k-1个结点(由二叉树的性质2可得出)
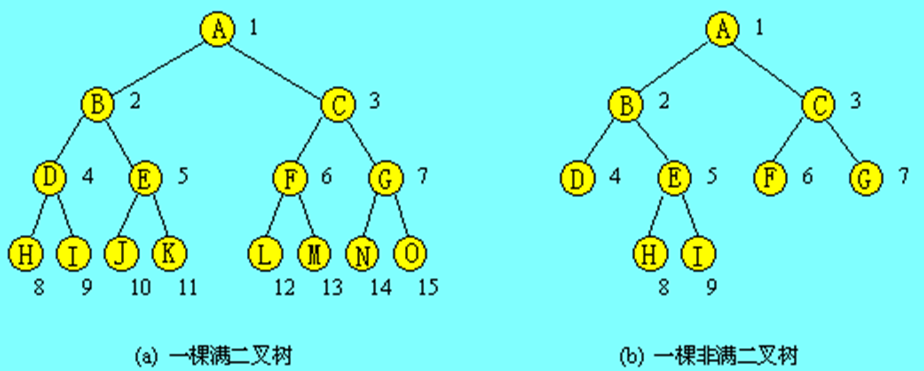
完全二叉树
完全二叉树的特点是叶子结点只能出现在最下层和次最下层,并且最下面一层上的结点都集中在该层最左边的若干位置上,至多只有最下面的两层上结点的度数可以小于2,满二叉树肯定是完全二叉树,而完全二叉树未必是满二叉树。
平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树,它保证了树的高度尽可能小,从而使得查找、插入和删除操作的时间复杂度保持在 O(log n) 的范围内。平衡二叉树的定义如下:
- 平衡因子 :每个节点的左子树和右子树的高度差不超过1。
- 高度平衡 :对于树中的每一个节点,其左子树和右子树的高度差的绝对值不超过1。
性质
性质1:在二叉树的第i层上至多有2^(i-1)个结点
性质2:深度为k的二叉树至多有2^k-1个结点
性质3: 对于任何一棵二叉树,若2度的结点数有n2个,则叶子数n0必定为n2+1 (即n0=n2+1)
每个2度结点产生2个结点,如果产生的结点为2度结点,那么它自身产生的一个额外新结点与自己抵消,那么就是除根结点,每个2度结点对应一个叶子节点,即n0=n2+1
性质4:具有n个结点的完全二叉树的深度为[log2(n)]+1。
性质5:一棵具有n个结点的完全二叉树(又称顺序二叉树),对其结点按层从上至下(每层从左至右)进行1至n的编号,则对任一结点i(1<=i<=n)有:
(1)若i>1,则i的双亲是i/2;若i=1,则i是根,无双亲。
(2)若2i<=n,则i的左孩子是2i;否则, i无左孩子。
(3)若2i+1<=n,则i的右孩子是2i+1;否则, i无右孩子。
当然,在数组从下标0开始存储的情况时,左孩子变为2i+1,右孩子变为2i+2,但是在寻找双亲时需要通过mod2,而不是简单地除2来寻找。
二叉树的顺序存储
对于一般的二叉树,如果仍按从上至下和从左到右的顺序将树中的结点顺序存储在一维数组中,则数组元素下标之间的关系不能够反映二叉树中结点之间的逻辑关系,只有增添一些并不存在的空结点,使之成为一棵完全二叉树的形式,然后再用一维数组顺序存储。
显然,完全二叉树和满二叉树采用顺序存储比较合适。对于需增加许多空结点才能将一棵二叉树改造成为一棵完全二叉树的存储时,会造成空间的大量浪费,不宜用顺序存储结构。
极端情况是单支树,如一棵深度为k的右单支树,只有k个结点,却需分配2k-1个存储单元。
二叉树的链式存储
(1)二叉链表存储
链表中每个结点有3个域组成,除了数据域外,还有两个指针域,分别给出该结点左孩子和右孩子所在的链结点的存储地址。
(2)三叉链表存储
二叉链表存储可以直接找到结点的孩子结点,但不能直接找到其双亲结点,加入parent指针,用三叉链表存储可以解决这一问题,给运算带来方便
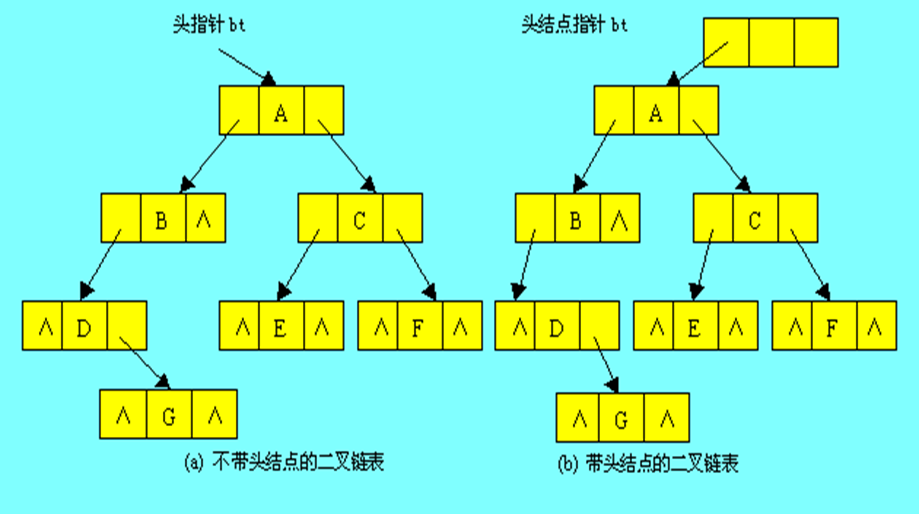
图(a)给出一棵二叉树的二叉链表存储表示。
二叉链表也可以带头结点的方式存放,如图(b)所示,根结点的地址存放在头结点的左孩子指针域。
二叉树基本实现
1、Initiate():建立一棵空的二叉树bt,并返回bt。
建立一棵空的带头结点的二叉树
1 | BiTree Initiate () //初始建立一棵带头结点的二叉树 |
建立不带头结点的二叉树
1 | BiTree Initiate () //初始建立一棵不带头结点的二叉树 |
2、Create(x,lbt,rbt):生成一棵以x为根结点的数据域值,以lbt和rbt为左右子树的二叉树。
1 | BiTree Create(elemtype x, BiTree lbt, BiTree rbt) |
3、InsertL(bt,x, parent):在二叉树bt中的parent所指结点和其左子树之间插入数据元素为x的结点,且原左子树作为X结点的左子树)
1 | BiTree InsertL(BiTree bt,elemtype x,BiTree parent) |
遍历二叉树
遍历定义–指按某条搜索路线遍访每个结点且不重复(又称周游)
遍历用途–树结构插入、删除、修改、查找和排序运算的前提,二叉树一切运算的基础和核心
遍历规则
DLR—先序遍历,即先根再左再右,先根序(中左右)
LDR—中序遍历,即先左再根再右,中根序(左中右)
LRD—后序遍历,即先左再右再根,后根序(左右中)
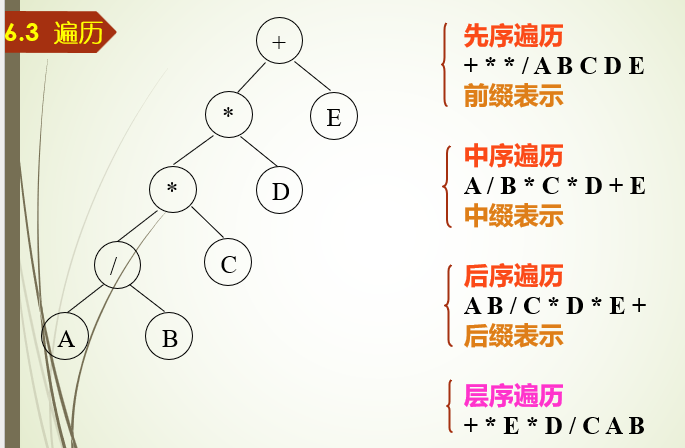
遍历的算法实现
先序遍历
1 | Status PreOrderTraverse(BiTree T) |
中序遍历
1 | Status InOrderTraverse(BiTree T) |
后序遍历
1 | Status PostOrderTraverse(BiTree T) |
如果去掉输出语句,从递归的角度看,三种算法的访问路径是相同的,只是访问结点的时机不同。即从根结点左外侧开始,由根结点右外侧结束的曲线,称其为该二叉树的包络线。
非递归改递归算法的查找树
1 | Status PreOrderTraverse(BiTree T) |
1 | Status InOrderTraverse(BiTree T) |
1 | Status PostOrderTraverse(BiTree T) |
层序遍历
所谓二叉树的层次遍历,是指从二叉树的第一层(根结点)开始,从上至下逐层遍历,在同一层中,则按从左到右的顺序对结点逐个访问。
所以我们采用用队列进行记录
1、从根开始,访问当前结点,将lchild和rchild入队列;
2、从队列头取出结点访问,将此结点的lchild和rchild入队列;
3、不断重复2,直到队列空。
简单来说其实只有一个while循环
1 | queue<BiTree> q; |
每一次将队列头节点的两个子节点入队,从而保证了层序遍历的优先级别
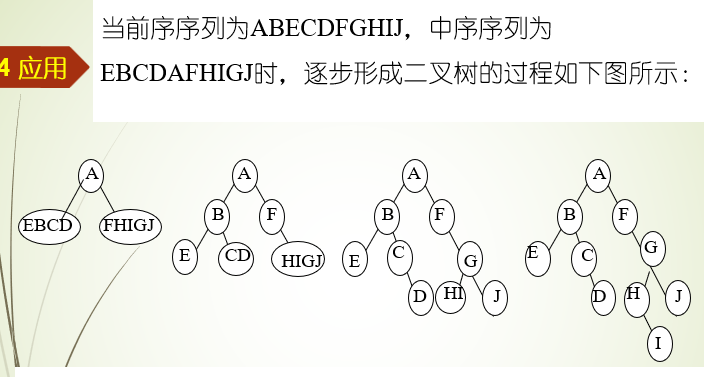
确定二叉树
先序+中序/中序+后序可以直接确定一颗二叉树,但先序+后序不行
先序遍历和后序遍历不能唯一确定一棵树的原因是,这两种遍历方式都无法提供足够的信息来唯一确定树的结构。具体来说:
- 先序遍历 (Preorder Traversal)给出了根节点的顺序,但没有提供子树的边界信息。
- 后序遍历 (Postorder Traversal)给出了叶节点的顺序,但同样没有提供子树的边界信息。
由于缺乏子树的边界信息,单独使用先序和后序遍历无法唯一确定树的结构。例如,考虑以下两棵不同的树:
1 | 树1: |
对于这两棵树,先序遍历和后序遍历的结果是相同的:
- 先序遍历(Preorder):A, B, D, C, E
- 后序遍历(Postorder):D, B, E, C, A
而中序遍历(Inorder Traversal)提供了节点在树中的相对位置关系,特别是根节点与其左右子树之间的关系。具体来说,中序遍历的结果可以帮助我们确定以下几点:
- 根节点的位置 : 在中序遍历中,根节点位于其左子树和右子树之间。通过找到根节点的位置,我们可以将中序遍历结果分割成左子树和右子树的中序遍历结果。
- 子树的边界 : 通过根节点的位置,我们可以确定左子树和右子树的边界,从而进一步递归地构建左右子树。
因此,中序遍历提供了关键的结构信息,使得结合先序遍历或后序遍历可以唯一确定一棵树。
借助栈沿着包络线走
从根结点开始沿左子树深入下去,当深入到最左端,无法再深入下去时,则返回,再逐一进入刚才深入时遇到结点的右子树,再进行如此的深入和返回,直到最后从根结点的右子树返回到根结点为止。
在这一过程中,返回结点的顺序如深入结点的顺序想法,即后深入先返回。符合“栈”结构的特点
1 | 【算法 6-8】先序遍历的非递归算法 |
中序和后序同理
由遍历序列恢复二叉树
前提条件:任意一棵二叉树结点的先序序列和中序序列都是唯一的
恢复二叉树有以下情况

即依据遍历定义:
- 由二叉树的先序序列和中序序列可唯一地确定该二叉树。
- 由二叉树的后序序列和中序序列也可唯一地确定该二叉树。
- 由二叉树的先序序列和后序序列不能唯一地确定该二叉树。
先序+中序转后序
核心思路:先根据先序序列的第一个元素建立根结点,然后在中序序列中找到该元素,确定根结点的左、右子树的中序序列,再在先序序列中确定左、右子树的先序序列;最后递归调用分别恢复左子树和右子树。
中序+后序转先序
①由后序遍历特征,根结点必在后序序列尾部(A);
②由中序遍历特征,根结点必在其中间,而且其左部必全部是左子树子孙(BDCE),其右部必全部是右子树子孙(FHG);
③继而,根据后序中的DECB子树可确定B为A的左孩子,根据HGF子串可确定F为A的右孩子;以此类推。
- Title: 树和二叉树
- Author: time will tell
- Created at : 2024-10-27 19:14:03
- Updated at : 2024-11-16 17:34:42
- Link: https://sbwrn.github.io/2024/10/27/二叉树/
- License: This work is licensed under CC BY-NC-SA 4.0.